
Attention和Transformer
1.Self-Attention
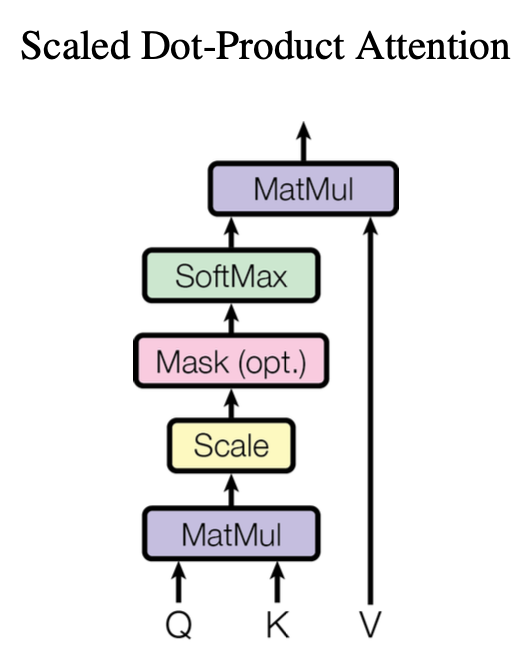
参考Keras官方文档:https://keras.io/api/layers/attention_layers/attention/
论文公式:
$$
Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d_k}})V
$$
构造参数:
- use_scale=False: scale指的是公式中的$\sqrt{d_k} $部分。默认为False,不会进行scale。如果为True,会创建一个可训练的变量来做scale
- causal: Boolean类型,主要用在decoder中。如果设置为True,会创建一个倒三角形状的mask。
调用参数:
- inputs: [q, v, k]的列表,k可以为空,默认等于v。
- mask: [q_mask, v_mask]列表,
假设输入 q = [batch_size, Tq, dim], v = [batch_size, Tv, dim], k = [batch_size, Tv, dim].
则输出 result = [batch_size, Tq, dim]
1 | import tensorflow as tf |
1 | input = tf.keras.Input(shape=(256,)) |
Model: "model_4"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_7 (InputLayer) [(None, 256)] 0 []
embedding_10 (Embedding) (None, 256, 16) 160000 ['input_7[0][0]']
attention_2 (Attention) (None, 256, 16) 1 ['embedding_10[0][0]',
'embedding_10[0][0]']
attention_3 (Attention) (None, 256, 16) 1 ['attention_2[0][0]',
'attention_2[0][0]']
global_average_pooling1d_4 (Gl (None, 16) 0 ['attention_3[0][0]']
obalAveragePooling1D)
dense_8 (Dense) (None, 2) 34 ['global_average_pooling1d_4[0][0
]']
==================================================================================================
Total params: 160,036
Trainable params: 160,036
Non-trainable params: 0
__________________________________________________________________________________________________
Epoch 1/20
30/30 [==============================] - 2s 41ms/step - loss: 0.6911 - accuracy: 0.5694 - val_loss: 0.6886 - val_accuracy: 0.6503
Epoch 2/20
30/30 [==============================] - 1s 37ms/step - loss: 0.6852 - accuracy: 0.6934 - val_loss: 0.6823 - val_accuracy: 0.7106
Epoch 3/20
30/30 [==============================] - 1s 36ms/step - loss: 0.6768 - accuracy: 0.7365 - val_loss: 0.6730 - val_accuracy: 0.7323
Epoch 4/20
30/30 [==============================] - 1s 36ms/step - loss: 0.6646 - accuracy: 0.7499 - val_loss: 0.6600 - val_accuracy: 0.7399
Epoch 5/20
30/30 [==============================] - 1s 31ms/step - loss: 0.6480 - accuracy: 0.7581 - val_loss: 0.6426 - val_accuracy: 0.7454
Epoch 6/20
30/30 [==============================] - 1s 31ms/step - loss: 0.6263 - accuracy: 0.7635 - val_loss: 0.6202 - val_accuracy: 0.7486
Epoch 7/20
30/30 [==============================] - 1s 36ms/step - loss: 0.5987 - accuracy: 0.7675 - val_loss: 0.5919 - val_accuracy: 0.7623
Epoch 8/20
30/30 [==============================] - 1s 36ms/step - loss: 0.5626 - accuracy: 0.7833 - val_loss: 0.5542 - val_accuracy: 0.7758
Epoch 9/20
30/30 [==============================] - 1s 32ms/step - loss: 0.5179 - accuracy: 0.7997 - val_loss: 0.5088 - val_accuracy: 0.7938
Epoch 10/20
30/30 [==============================] - 1s 36ms/step - loss: 0.4665 - accuracy: 0.8207 - val_loss: 0.4566 - val_accuracy: 0.8185
Epoch 11/20
30/30 [==============================] - 1s 32ms/step - loss: 0.4087 - accuracy: 0.8449 - val_loss: 0.3990 - val_accuracy: 0.8420
Epoch 12/20
30/30 [==============================] - 1s 31ms/step - loss: 0.3526 - accuracy: 0.8658 - val_loss: 0.3532 - val_accuracy: 0.8568
Epoch 13/20
30/30 [==============================] - 1s 36ms/step - loss: 0.3119 - accuracy: 0.8798 - val_loss: 0.3266 - val_accuracy: 0.8673
Epoch 14/20
30/30 [==============================] - 1s 36ms/step - loss: 0.2873 - accuracy: 0.8867 - val_loss: 0.3129 - val_accuracy: 0.8738
Epoch 15/20
30/30 [==============================] - 1s 36ms/step - loss: 0.2710 - accuracy: 0.8912 - val_loss: 0.3045 - val_accuracy: 0.8770
Epoch 16/20
30/30 [==============================] - 1s 31ms/step - loss: 0.2580 - accuracy: 0.8961 - val_loss: 0.2983 - val_accuracy: 0.8806
Epoch 17/20
30/30 [==============================] - 1s 31ms/step - loss: 0.2471 - accuracy: 0.9017 - val_loss: 0.2944 - val_accuracy: 0.8822
Epoch 18/20
30/30 [==============================] - 1s 36ms/step - loss: 0.2369 - accuracy: 0.9073 - val_loss: 0.2917 - val_accuracy: 0.8839
Epoch 19/20
30/30 [==============================] - 1s 31ms/step - loss: 0.2279 - accuracy: 0.9110 - val_loss: 0.2893 - val_accuracy: 0.8840
Epoch 20/20
30/30 [==============================] - 1s 37ms/step - loss: 0.2190 - accuracy: 0.9157 - val_loss: 0.2882 - val_accuracy: 0.8852
2.MultiHeadAttention
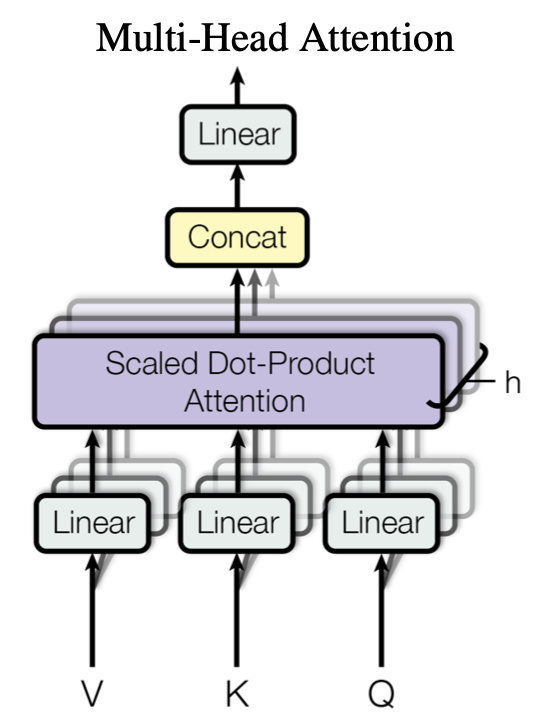
参考keras官方文档:https://keras.io/api/layers/attention_layers/multi_head_attention/
初始化关键参数:
- num_heads :使用多少个头
- key_dim :每个头的K第一个Dense层的维度
- value_dim=None, 每个头的V第一个Dense层的维度,可以为空。Self-Attention的话V=K,就可以不用填。
- output_shape=None, 输出的维度,对应最后一层的Dense维度,默认等于输入的维度。
这里没有说query_dim,根据源码query_dim=key_dim。(因为Q要和K的转置矩阵相乘,所以必须一样)
调用关键参数:
- query : Q, shape=(B, T, dim).
- value : V, shape=(B, S, dim).
- key=None : K, shape=(B, S, dim). 为None时等于V.
假设输入Q=(B, T, dim),V=(B, S, dim),K=(B, S, dim)。
则经过第一层Dense之后,输出是Q’= (B, T, key_dim),V’=(B, S, value_dim),K’=(B, S, key_dim).
经过attention层之后,输出是attention_result = (B, T, value_dim).
经过Concat层之后,输出concat = (B, T, value_dim * num_heads).
经过最后一层Dense之后,输出 result = (B, T, output_shape).
1 | input = tf.keras.Input(shape=(256,)) |
Model: "model_5"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_8 (InputLayer) [(None, 256)] 0 []
embedding_11 (Embedding) (None, 256, 16) 160000 ['input_8[0][0]']
multi_head_attention_5 (MultiH (None, 256, 16) 284 ['embedding_11[0][0]',
eadAttention) 'embedding_11[0][0]']
multi_head_attention_6 (MultiH (None, 256, 20) 304 ['multi_head_attention_5[0][0]',
eadAttention) 'multi_head_attention_5[0][0]']
global_average_pooling1d_5 (Gl (None, 20) 0 ['multi_head_attention_6[0][0]']
obalAveragePooling1D)
dense_9 (Dense) (None, 2) 42 ['global_average_pooling1d_5[0][0
]']
==================================================================================================
Total params: 160,630
Trainable params: 160,630
Non-trainable params: 0
__________________________________________________________________________________________________
Epoch 1/10
30/30 [==============================] - 3s 71ms/step - loss: 0.6933 - accuracy: 0.4964 - val_loss: 0.6932 - val_accuracy: 0.4947
Epoch 2/10
30/30 [==============================] - 2s 66ms/step - loss: 0.6915 - accuracy: 0.5567 - val_loss: 0.6877 - val_accuracy: 0.7045
Epoch 3/10
30/30 [==============================] - 2s 55ms/step - loss: 0.6688 - accuracy: 0.7019 - val_loss: 0.6346 - val_accuracy: 0.7139
Epoch 4/10
30/30 [==============================] - 2s 55ms/step - loss: 0.5510 - accuracy: 0.7667 - val_loss: 0.4797 - val_accuracy: 0.7833
Epoch 5/10
30/30 [==============================] - 2s 55ms/step - loss: 0.3825 - accuracy: 0.8382 - val_loss: 0.3599 - val_accuracy: 0.8478
Epoch 6/10
30/30 [==============================] - 2s 55ms/step - loss: 0.2829 - accuracy: 0.8871 - val_loss: 0.3200 - val_accuracy: 0.8714
Epoch 7/10
30/30 [==============================] - 2s 55ms/step - loss: 0.2363 - accuracy: 0.9073 - val_loss: 0.3078 - val_accuracy: 0.8786
Epoch 8/10
30/30 [==============================] - 2s 55ms/step - loss: 0.2000 - accuracy: 0.9245 - val_loss: 0.3040 - val_accuracy: 0.8828
Epoch 9/10
30/30 [==============================] - 2s 55ms/step - loss: 0.1689 - accuracy: 0.9388 - val_loss: 0.3101 - val_accuracy: 0.8851
Epoch 10/10
30/30 [==============================] - 2s 55ms/step - loss: 0.1441 - accuracy: 0.9494 - val_loss: 0.3257 - val_accuracy: 0.8847
3.Transformer
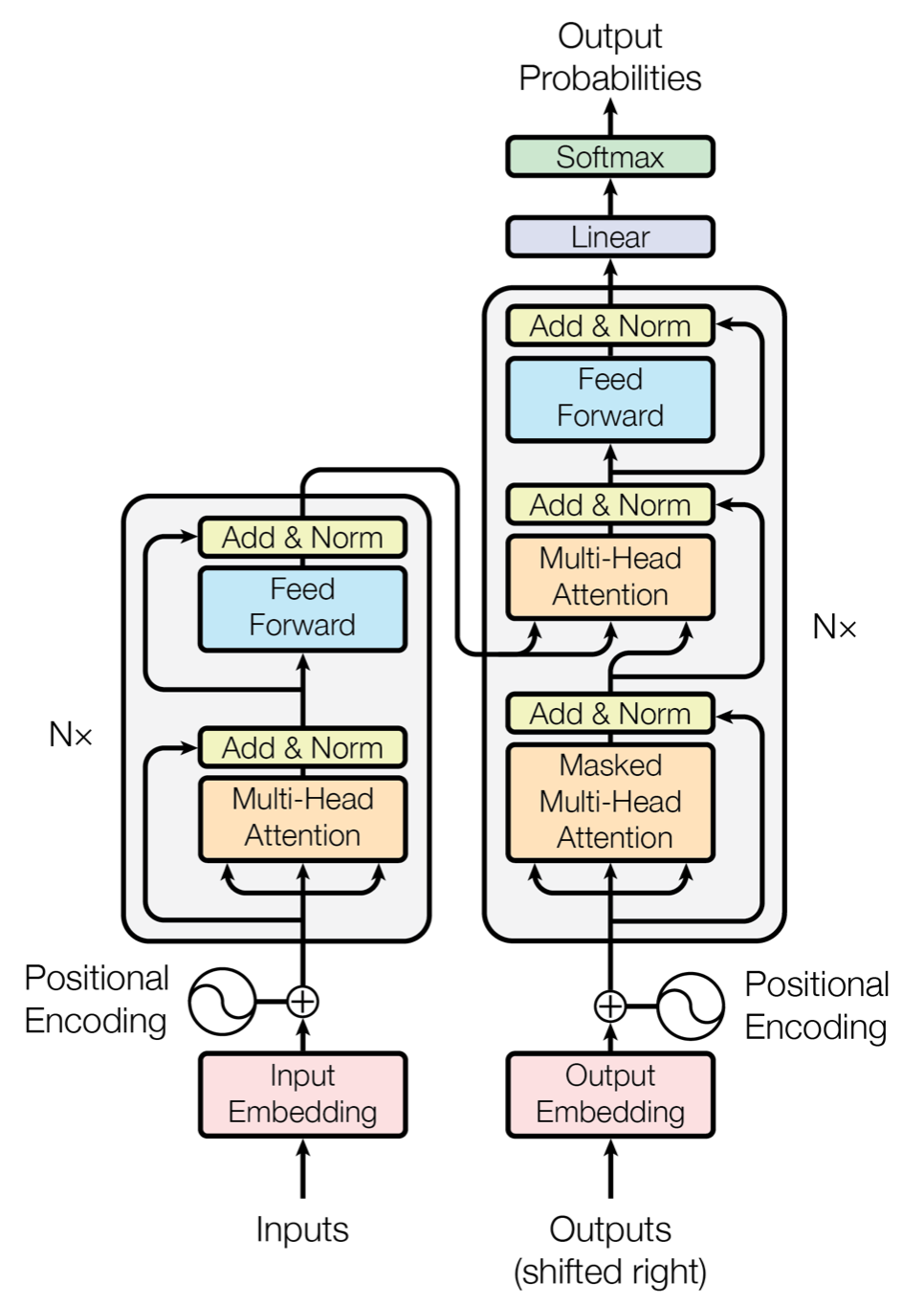
Transformer(左)分为两个sub-layer。第一个是MultiHeadAttention的残差模块,最后经过一个LayerNormalization。第二个是FFN的残差模块,其中包含两个Dense层。
Transformer在Keras可以直接引用的类,可以参考Example里的实现:https://keras.io/examples/nlp/text_classification_with_transformer/
1 | class TransformerBlock(layers.Layer): |
1 | embed_dim = 16 |
Model: "model_6"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_9 (InputLayer) [(None, 256)] 0
embedding_12 (Embedding) (None, 256, 16) 160000
transformer_block_3 (Transf (None, 256, 16) 4352
ormerBlock)
global_average_pooling1d_6 (None, 16) 0
(GlobalAveragePooling1D)
dense_12 (Dense) (None, 2) 34
=================================================================
Total params: 164,386
Trainable params: 164,386
Non-trainable params: 0
_________________________________________________________________
Epoch 1/10
30/30 [==============================] - 2s 49ms/step - loss: 0.6453 - accuracy: 0.6542 - val_loss: 0.5804 - val_accuracy: 0.7218
Epoch 2/10
30/30 [==============================] - 1s 42ms/step - loss: 0.4940 - accuracy: 0.8055 - val_loss: 0.4534 - val_accuracy: 0.7943
Epoch 3/10
30/30 [==============================] - 1s 42ms/step - loss: 0.3218 - accuracy: 0.8714 - val_loss: 0.3023 - val_accuracy: 0.8703
Epoch 4/10
30/30 [==============================] - 1s 42ms/step - loss: 0.2155 - accuracy: 0.9139 - val_loss: 0.3076 - val_accuracy: 0.8729
Epoch 5/10
30/30 [==============================] - 1s 42ms/step - loss: 0.1466 - accuracy: 0.9483 - val_loss: 0.3215 - val_accuracy: 0.8767
Epoch 6/10
30/30 [==============================] - 1s 42ms/step - loss: 0.1057 - accuracy: 0.9649 - val_loss: 0.3564 - val_accuracy: 0.8784
Epoch 7/10
30/30 [==============================] - 1s 42ms/step - loss: 0.0778 - accuracy: 0.9763 - val_loss: 0.4053 - val_accuracy: 0.8732
Epoch 8/10
30/30 [==============================] - 1s 42ms/step - loss: 0.0503 - accuracy: 0.9872 - val_loss: 0.4719 - val_accuracy: 0.8704
Epoch 9/10
30/30 [==============================] - 1s 42ms/step - loss: 0.0376 - accuracy: 0.9906 - val_loss: 0.5576 - val_accuracy: 0.8607
Epoch 10/10
30/30 [==============================] - 1s 42ms/step - loss: 0.0551 - accuracy: 0.9811 - val_loss: 0.6259 - val_accuracy: 0.8409
4.Posiotnal Embedding
因为attention缺少位置信息,所以在输入中需要人为额外加入位置的信息。
论文中Positional Encoding是由一个三角函数算出,非常难理解,参考:https://www.zhihu.com/question/347678607
好在Bert中使用了Positonal Embedding。
1 | class PositionalEmbedding(layers.Layer): |
1 | embed_dim = 16 |
Model: "model_7"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_10 (InputLayer) [(None, 256)] 0
embedding_13 (Embedding) (None, 256, 16) 160000
positional_embedding_4 (Pos (None, 256, 16) 4096
itionalEmbedding)
transformer_block_4 (Transf (None, 256, 16) 4352
ormerBlock)
global_average_pooling1d_7 (None, 16) 0
(GlobalAveragePooling1D)
dense_15 (Dense) (None, 2) 34
=================================================================
Total params: 168,482
Trainable params: 168,482
Non-trainable params: 0
_________________________________________________________________
Epoch 1/10
30/30 [==============================] - 3s 50ms/step - loss: 0.6836 - accuracy: 0.5669 - val_loss: 0.6342 - val_accuracy: 0.6866
Epoch 2/10
30/30 [==============================] - 1s 43ms/step - loss: 0.5686 - accuracy: 0.7971 - val_loss: 0.4979 - val_accuracy: 0.8068
Epoch 3/10
30/30 [==============================] - 1s 42ms/step - loss: 0.3746 - accuracy: 0.8607 - val_loss: 0.3159 - val_accuracy: 0.8717
Epoch 4/10
30/30 [==============================] - 1s 42ms/step - loss: 0.2352 - accuracy: 0.9043 - val_loss: 0.2971 - val_accuracy: 0.8763
Epoch 5/10
30/30 [==============================] - 1s 42ms/step - loss: 0.1669 - accuracy: 0.9396 - val_loss: 0.3304 - val_accuracy: 0.8711
Epoch 6/10
30/30 [==============================] - 1s 43ms/step - loss: 0.1243 - accuracy: 0.9583 - val_loss: 0.3271 - val_accuracy: 0.8796
Epoch 7/10
30/30 [==============================] - 1s 42ms/step - loss: 0.0952 - accuracy: 0.9687 - val_loss: 0.4539 - val_accuracy: 0.8557
Epoch 8/10
30/30 [==============================] - 1s 42ms/step - loss: 0.0709 - accuracy: 0.9792 - val_loss: 0.4123 - val_accuracy: 0.8745
Epoch 9/10
30/30 [==============================] - 1s 42ms/step - loss: 0.0486 - accuracy: 0.9873 - val_loss: 0.5071 - val_accuracy: 0.8647
Epoch 10/10
30/30 [==============================] - 1s 42ms/step - loss: 0.0421 - accuracy: 0.9881 - val_loss: 0.5244 - val_accuracy: 0.8679
