
推荐系统笔记
1.架构示意图
推荐系统的技术架构示意图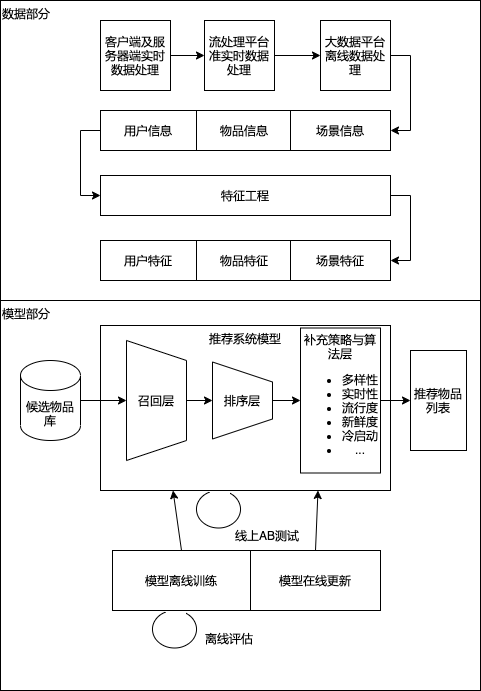
推荐系统的数据部分主要负责“用户”“物品”“场景”的信息收集与处理。在得到原始的数据信息后,推荐系统的数据处理系统会将原始数据进一步加工,加工后的数据出口主要有三个:
- 生成推荐模型所需的样本数据,用于算法模型的训练和评估。
- 生成推荐模型服务所需的“特征”,用于推荐系统的线上推断。
- 生成系统监控、商业智能(Business Intelligence, BI)系统所需的统计型数据。
推荐系统的模型部分是推荐系统的主题,一般由“召回层”“排序层”“补充策略与算法层”组成。
- 召回层一般利用高效的召回规则、算法或简单的模型,快速从海量的候选集中召回用户可能感兴趣的物品。
- 排序层利用排序模型对初筛的候选集进行精排序。
- 补充策略与算法层,也被称为再排序层,可以在将推荐列表返回用户之前,为兼顾结果的多样性、流行度、新鲜度等指标,结合一些补充的策略和算法对推荐列表进行一定的调整,最终形成用户可见的推荐列表。
在线环境进行模型服务之前,需要通过模型训练确定模型结构、结构中不同参数权重的具体数值,以及模型相关算法和策略中的参数取值。模型训练方法又可以根据模型训练环境的不同,分为“离线训练”和“在线训练”两部分,其中:离线训练的特点是可以利用全量样本的特征,使模型逼近全局最优点;在线更新则可以准实时地“消化”新的数据样本,更快地反映新的数据变化趋势,满足模型实时性的需求。
为了评估模型的效果,方便模型的迭代优化,推荐系统的模型部分提供了“离线评估”和“线上A/B测试”等多种评估模块,用得出的线下和线上评估指标,指导下一步的模型迭代优化。
2.召回层
推荐系统的模型部分将推荐过程分为召回层和排序层的主要原因是基于工程上的考虑。在排序阶段,一般会使用复杂的模型,利用多特征进行精确排序,而在这一过程中,如果直接对百万量级的候选集进行逐一推断,则计算资源和延迟都是在线服务过程无法忍受的。因此加入召回过程,利用少量的特征和简单的模型或规则进行候选集的快速筛选,减少精准排序阶段的时间开销。
在设计召回层时,计算速度和召回率其实是矛盾的两个指标,为提高计算速度,需要使用召回策略尽量简单;而为了提高召回率,要求召回策略能够尽量选出排序模型需要的候选集。这又要求召回策略不能过于简单,导致召回物品无法满足排序模型的要求。
在权衡计算速度和召回率后,目前工业界主流的召回方法是采用多个简单策略叠加的“多路召回策略”。
2.1多路召回策略
所谓多路召回策略,就是指采用不同的策略、特征或简单模型,分别召回一部分候选集,然后把候选集混合在一起供后续排序模型使用的策略。
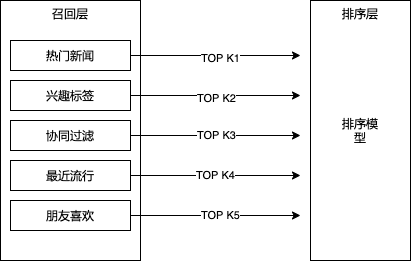
每一路召回策略会拉回K个候选物品,对于不同的召回策略,K值可以选择不同的大小。这里的K是超参数,一般需要通过离线评估加线上A/B测试的方式确定合理的取值范围。
2.2基于embedding的召回方法
利用深度学习网络生成的Embedding作为召回层的方法。
3.排序层
在互联网永不停歇的增长需求的驱动下,推荐系统的发展可谓一日千里,从2010年之前千篇一律的协同过滤、逻辑回归、进化到因子分解机、梯度提升树,再到2015年之后深度学习推荐模型的百花齐放,各种模型架构层出不穷。推荐系统的主流模型经历了从单一模型到组合模型,从经典框架到深度学习的发展过程。
非深度学习模型
| 模型名称 | 基本原理 | 特点 | 局限性 |
|---|---|---|---|
| 协同过滤 | 根据用户的行为历史生成用户-物品共现矩阵,利用用户相似性和物品相似性进行推荐 | 原理简单、直接,应用广泛 | 泛化能力差,处理稀疏矩阵的能力差,推荐结果的头部效应较明显 |
| 矩阵分解 | 将协同过滤算法中的共现矩阵分解为用户矩阵和物品矩阵,利用用户隐向量和物品隐向量的内积进行排序并推荐 | 相交协同过滤,泛化能力有所加强,对稀疏矩阵的处理能力有所加强 | 除了用户历史行为数据,难以利用其它用户、物品特征及上下文特征 |
| 逻辑回归 | 将推荐问题转换成类似CTR预估的二分类问题,将用户、物品、上下文等不同特征转换成特征向量,输入逻辑回归模型得到CTR,再按照预估CTR进行排序并推荐 | 能够融合多种类型的不同特征 | 模型不具备特征组合的能力,表达能力较差 |
| FM | 在逻辑回归的基础上,在模型中加入二阶特征交叉部分,为每一位特征训练得到相应特征隐向量,通过隐向量间的内积运算得到交叉特征权重 | 相比逻辑回归,具备了二阶特征交叉能力,模型的表达能力增强 | 由于组合爆炸问题的限制,模型不易扩展到三阶特征交叉阶段 |
| FFM | 在FM模型的基础上,加入“特征域”的概念,使每个特征在不同域的特征交叉时采用不同的隐向量 | 相比FM,进一步加强了特征交叉的能力 | 模型的训练开销达到了O(n^2)的量级,训练开销大。 |
| GBDT+LR | 利用GBDT进行“自动化”的特征组合,将原始特征向量转换成离散型特征向量,并输入逻辑回归模型,进行最终的CTR预估 | 特征模型化,使模型具备了更高阶特征组合的能力 | GBDT无法进行完全并行的训练,更新所需的训练时间较长 |
| LS-PLM | 首选对样本进行“分片”,在每个“分片”内部构件逻辑回归模型,将每个样本的各“分片”概率与逻辑回归的得分进行加权平均,得到最终的预估值 | 模型结构类似三层神经网络,具备了较强的表达能力 | 模型结构相比深度学习模型仍比较简单,有进一步提高的空间 |
基于深度学习的模型
| 模型名称 | 基本原理 | 特点 | 局限性 |
|---|---|---|---|
| AutoRec | 基于自编码器,对用户或者物品进行编码,利用自编码器的泛化能力进行推荐 | 单隐层神经网络结构简单,可实现快速训练和部署 | 表达能力较差 |
| Deep Crossing | 利用“Embedding层+多隐层+输出层”的经典深度学习框架,预完成特征的自动深度交叉 | 经典的深度学习推荐模型框架 | 利用全连接隐层进行特征交叉,针对性不强 |
| NeuralCF | 将传统的矩阵分解中用户向量和物品向量的点击操作,换成由神经网络代替的互操作 | 表达能力加强版的矩阵分解模型 | 只使用了用户和物品的id特征,没有加入更多其他特征 |
| PNN | 针对不同特征域之间的交叉操作,定义”内积“”外积“等多积操作 | 在经典深度学习框架上模型提高了特征交叉能力 | ”外积“操作进行近似化,一定程度上影响了其表达能力 |
| Wide&Deep | 利用Wide部分加强模型的”记忆能力“,利用Deep部分加强模型的”泛化能力“ | 开创了组合模型的构造方法,对深度学习推荐模型的后续发展产生重大影响 | Wide部分需要人工进行特征组合的筛选 |
| Dee&Cross | 用Cross网络替代Wide&Deep模型中的Wide部分 | 解决了Wide&Deep模型人工组合特征的问题 | Cross网络的复杂度比较高 |
| FNN | 利用FM的参数来初始化深度神经网络的Embedding层参数 | 利用FM初始化参数,加快整个网络的收敛速度 | 模型的主结构比较简单,没有针对性的特征交叉层 |
| DeepFM | 在Wide&Deep模型的基础上,用FM替代原来的线性Wide部分 | 加强了Wide部分的特征交叉能力 | 与经典的Wide&Deep模型相比,结构差别不明显 |
| NFM | 用神经网络替代FM中二隐向量交叉的操作 | 相比FM,NFM的表达能力和特征交叉能力更强 | 与PNN模型的结构非常相似 |
| AFM | 在FM的基础上,在二阶隐向量交叉的基础上对每个交叉结果加入了注意力得分,并使用注意力网络学习注意力得分 | 不同交叉特征的重要性不同 | 注意力网络的训练过程比较复杂 |
| DIN | 在传统深度学习推荐模型的基础上引入注意力机制,并利用用户行为历史物品和目标广告物品的相关性计算注意力得分 | 根据目标广告物品的不同,进行更有针对性的推荐 | 并没有充分利用除”历史行为“以外的其他特征 |
| DIEN | 将序列模型与深度学习推荐模型结合,使用序列模型模拟用户的兴趣进化过程 | 序列模型增强了系统对用于兴趣变迁的表达能力,使推荐系统开始考虑时间相关的行为序列中包含的有价值信息 | 序列模型的训练复杂,线上服务的延迟较长,需要进行工程上的优化 |
| DRN | 将强化学习的思路应用于推荐系统,进行推荐模型的线上实时学习和更新 | 模型对数据实时性的利用能力大大加强 | 线上部分较复杂,工程实现难度较大 |
4.特征
4.1用户行为数据
用户行为数据是推荐系统最常用,也是最关键的数据。一般分为显性反馈行为(explicit feedback)和隐性反馈行为(implicit feedback)两种。
| 业务场景 | 显性反馈行为 | 隐性反馈行为 |
|---|---|---|
| 电子商务网站 | 对商品的评分 | 点击、加入购物车、购买等 |
| 视频网站 | 对视频的评分、点赞等 | 点击、播放、播放时长等 |
| 新闻类网站 | 赞、踩等行为 | 点击、评论等 |
| 音乐网站 | 对歌曲、歌手、专辑的评分 | 点击、播放、收藏等 |
在当前的推荐系统特征工程中,隐性反馈行为越来越重要,主要原因是显性反馈行为的难度过大,数据量小。在深度学习模型对数据量的要求越来越大背景下,仅用显性反馈的数据不足以支持推荐系统训练过程的最终收敛。因此,能够反映用户行为特点的隐性反馈是目前特征挖掘的重点。
4.2上下文信息
上下文包括用户访问推荐系统的时间、地点、心情等,对于提高推荐系统是非常重要的。比如,一个卖衣服的推荐系统在冬天和夏天应该给用户推荐不同种类的衣服,用户上班时和下班后的兴趣会有区别。
4.2.1时间
时间是一种重要的上下文信息,对用户兴趣有着深入而广泛的影响。一般认为,时间信息对用户兴趣的影响表现在以下几个方面。
- 用户兴趣是变化的。一位程序员随着工作时间的增加,逐渐从阅读入门书籍过渡到阅读专业书籍。
- 物品也是有生命周期的。比如新闻的生命周期很短暂,而电影的生命周期相对较长。
- 季节效应。
4.2.2地点
除了时间,地点作为一种重要的空间特征,也是一种重要的上下文信息。不同地区的用户兴趣有所不同,用户到了不同的地方,兴趣也会有所不同。
5.冷启动
冷启动问题主要分3类:
- 用户冷启动。当心用户到来时,我们没有他的行为数据,所以也无法根据他的历史行为预测其兴趣,从而无法借此给他做个性化推荐。
- 物品冷启动。物品冷启动主要解决如何将新的物品推荐给可能对它感兴趣的用户这一问题。
- 系统冷启动。系统冷启动主要解决如何在一个新的开发的网站上设计个性化推荐系统,从而在网站刚发布时就让用户体验到个性化推荐服务这一问题。
解决方案:
- 提供非个性化的推荐。非个性化推荐的最简单例子就是热门排行榜,我们可以给用户推荐热门排行榜,然后等到用户数据收集到一定的时候,再切换为个性化推荐。
- 利用用户注册时提供的年龄、性别等数据做粗粒度的个性化。
- 利用用户的社交网络账号登录,导入用户在社交网络上的好友信息,然后给用户推荐其好友喜欢的物品。
- 要求用户在登录时对一些物品进行反馈,收集用户对这些物品的兴趣信息,然后给用户推荐那些和这些用户相似的物品。
- 对于新加入的物品,可以利用内容信息,将它们推荐给喜欢过和它们相似的物品和用户。
- 在系统冷启动时,可以引入专家的知识,通过一定的高效方式迅速建立起物品的相关度表。
- 利用主动学习、迁移学习和“探索与利用”机制。
6.实时性
推荐系统特征的实时性指的是“实时”地收集和更新推荐模型的输入特征,使推荐系统总能使用最新的特征进行预测和推荐。
举例来说,在一个短视频应用中,某用户完整地看完了一个长度为10分钟的“羽毛球教学”视频。毫无疑问,某用户对“羽毛球”这个主题是感兴趣的。系统希望立刻为用户继续推荐“羽毛球”相关视频。但是由于系统特征的实时性不强,用户的观看历史无法实时反馈给推荐系统,导致推荐系统得知该用户看过“羽毛球教学”这个视频已经是半个小时之后了,因此用户已经离开该应用,无法继续推荐。这就是一个因推荐实时性差异导致推荐失败的例子。
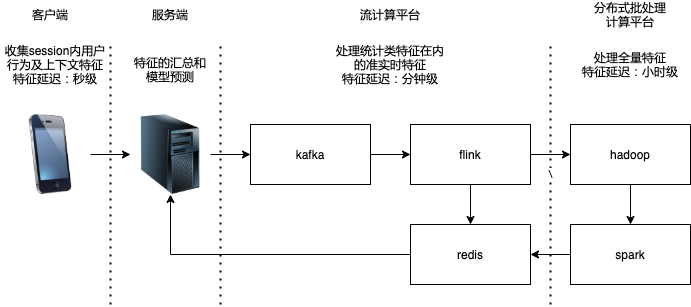
与特征的实时性相比,推荐系统模型的实时性往往是从更全局的角度考虑问题。特征的实时性力图用更准确的特征描述用户、物品和相关场景,从而让推荐系统给出更符合当时场景的推荐结果。而模型的实时性则是希望抓住全局层面的新数据模式,发现新的趋势和相关性。
模型的实时性是与模型的训练方式紧密相关的,由弱到强的训练方式分别是全量更新、增量更新、在线学习和局部更新。
全量更新是指模型利用某时间段内的所有训练样本进行训练,往往时间较长,因此是实时性最差的。
增量更新仅将新加入的样本“喂”给模型进行增量训练。深度学习往往采用梯度下降法及其变种进行学习,模型对增量样本的学习相当于在原有的样本基础上继续输入增量样本进行梯度下降。缺点是,增量更新的模型往往无法找到全局最优点,因此在实际使用中,往往采用增量和全局相结合的方式。在进行了几轮增量更新后,在业务量较少的时间窗口进行全局更新。
在线学习是在获得一个新的样本的同时更新模型,需要在线上环境进行模型的训练和大量模型相关参数的更新和存储,工程上的要求相对比较高。另一个方法是将强化学习与推荐系统结合。
局部更新是对模型的局部进行更新,较多应用在“Embedding层+神经网络”的模型中。Embedding层参数由于占据了深度学习模型参数的大部分,其训练过程会拖慢模型整体的收敛速度,因此业务往往采用Embedding层单独预训练,Embedding层以上的模型部分高频更新的混合策略。
7.离线评估
精确率和召回率
令R(u)是根据用户在训练集上的行为给用户作出的推荐列表,而T(u)是用户在测试集上的行为列表。那么推荐结果的召回率定义为:
推荐结果的精确率定义为:
F1
为了综合地反应Precision和recall的结果,可以使用F1-score,F1-score是精确率和召回率的调和平均值:
覆盖率
覆盖率是描述一个推荐系统对物品长尾的发掘能力。覆盖率有不同的定义方法,最简单的定义为推荐系统能够推荐出来的物品占总物品集合的比例。假设系统的用户集合为U,推荐系统给每个用户推荐一个长度为N的物品列表R(u)。那么推荐系统的覆盖率可以通过下面的公式计算:
此外,还有PR曲线,ROC曲线,多样性,新颖性等评估指标。
8.工程实现
从工程的角度看推荐系统,可以将其分为两大部分:数据部分和模型部分。数据部分主要指推荐系统所需数据流的先关工程实现;模型部分指的是推荐模型的相关工程实现。根据推荐系统的整体工程架构,可以分为三个部分:
- 推荐系统的数据流。主要是一些大数据流计算架构,有批处理、流计算、Lambda,Kappa4种架构。
- 深度学习推荐模型的离线训练。有Spark MLlib,Parameter Server,TensorFlow,PyTorch等。
- 深度学习推荐模型的上线部署
9.参考
- 王喆. 《深度学习推荐系统》.电子工业出版社.2020.3
- 项亮.《推荐系统实践》.人民邮电出版社.2012.6
